Most organizations still anchor their AI strategy around models. The discussion gravitates toward accuracy benchmarks, vendor selection, and whether to build proprietary capabilities or rely on external platforms.
This framing is incomplete. Across industries, a consistent pattern is emerging: organizations with access to the same models, often the same foundation models, are achieving materially different outcomes. Some are scaling AI across functions, embedding it into decision-making, and generating measurable impact. Others remain confined to pilots, with limited adoption and unclear return.
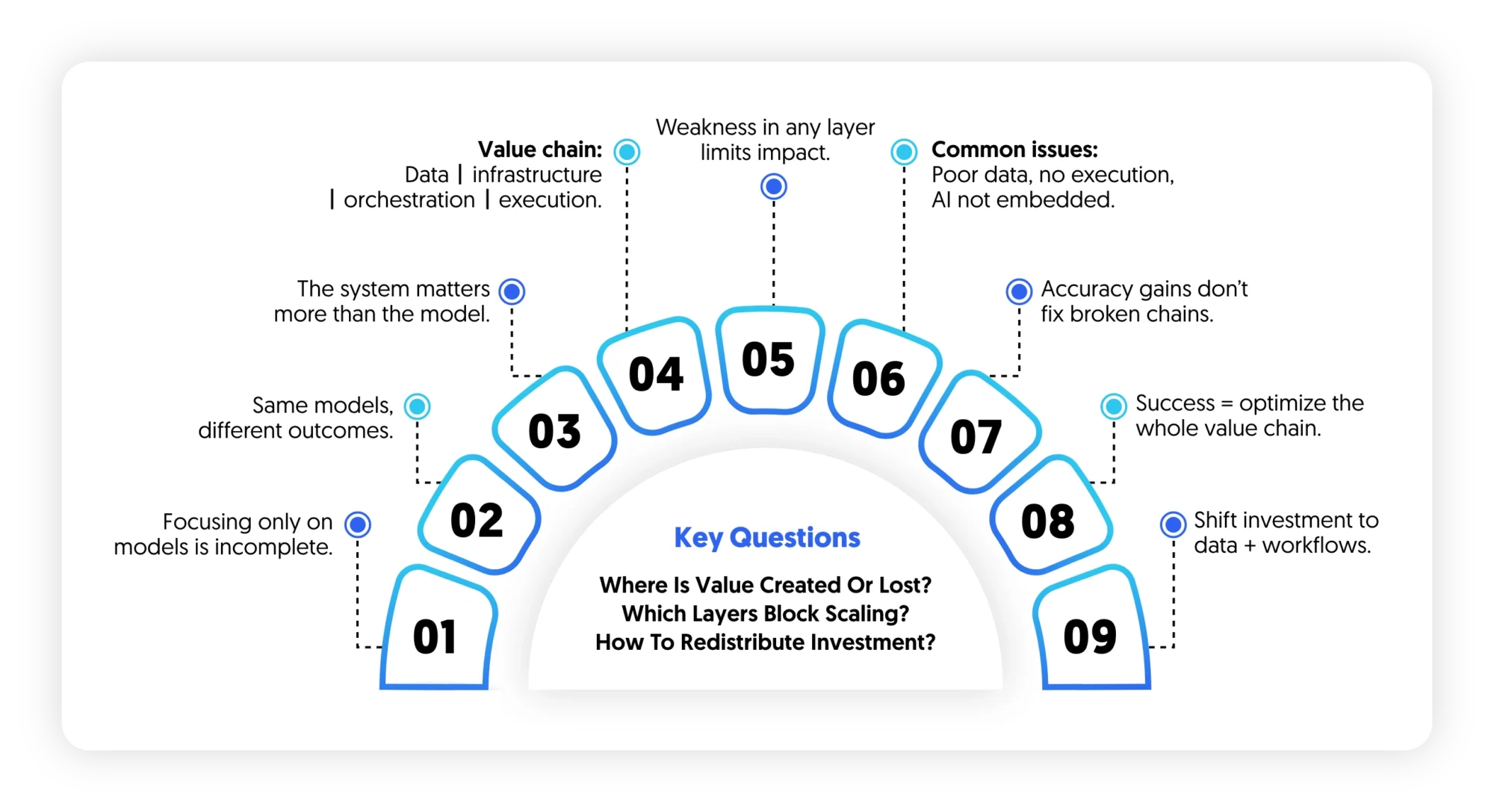
AI, in practice, behaves less like a discrete capability and more like a coordinated value chain, where each layer data, infrastructure, orchestration, and execution determines whether model outputs translate into business outcomes. Weakness in any layer constrains the entire system, regardless of model sophistication.
This misalignment explains why many AI programs underdeliver despite strong technical components. Organizations tend to concentrate investment in visible, high-prestige elements—models and compute—while underinvesting in less visible but more determinative layers such as data readiness and workflow integration.
The result is a structural imbalance:
- Advanced models operating on fragmented or low-quality data
- Insights generated without clear pathways to execution
- AI capabilities existing parallel to, rather than embedded within, core operations
In this context, improving model performance yields diminishing returns. Incremental gains in accuracy do not compensate for systemic gaps upstream or downstream.
A more effective lens is to treat AI not as a model selection problem, but as a value chain optimization problem. Value is only realized when all layers from data sourcing to real-time inference—are aligned and functioning cohesively.
This shift has direct implications for how AI investments are prioritized. It challenges the default sequencing of initiatives, where model development precedes data validation and integration planning. It also reframes success metrics, moving from technical performance indicators to operational and business outcomes.
Organizations that adopt this perspective tend to converge on a different set of questions:
- Where in the value chain is value actually created and where is it lost?
- Which layers constrain our ability to scale AI beyond pilots?
- How should investment be redistributed to unlock end-to-end impact?
Answering these questions requires a clear understanding of the AI value chain itself not as a technical architecture, but as an operational system.
The AI Value Chain, Deconstructed
Reframing AI as a value chain shifts the focus from components to interdependencies. Each layer does not operate in isolation; it either enables or constrains the layers above it. Value is not created at a single point, it emerges (or breaks) across the chain.
A closer look at each layer reveals where value is generated, where it is diluted, and why many AI systems fail to scale beyond controlled environments.
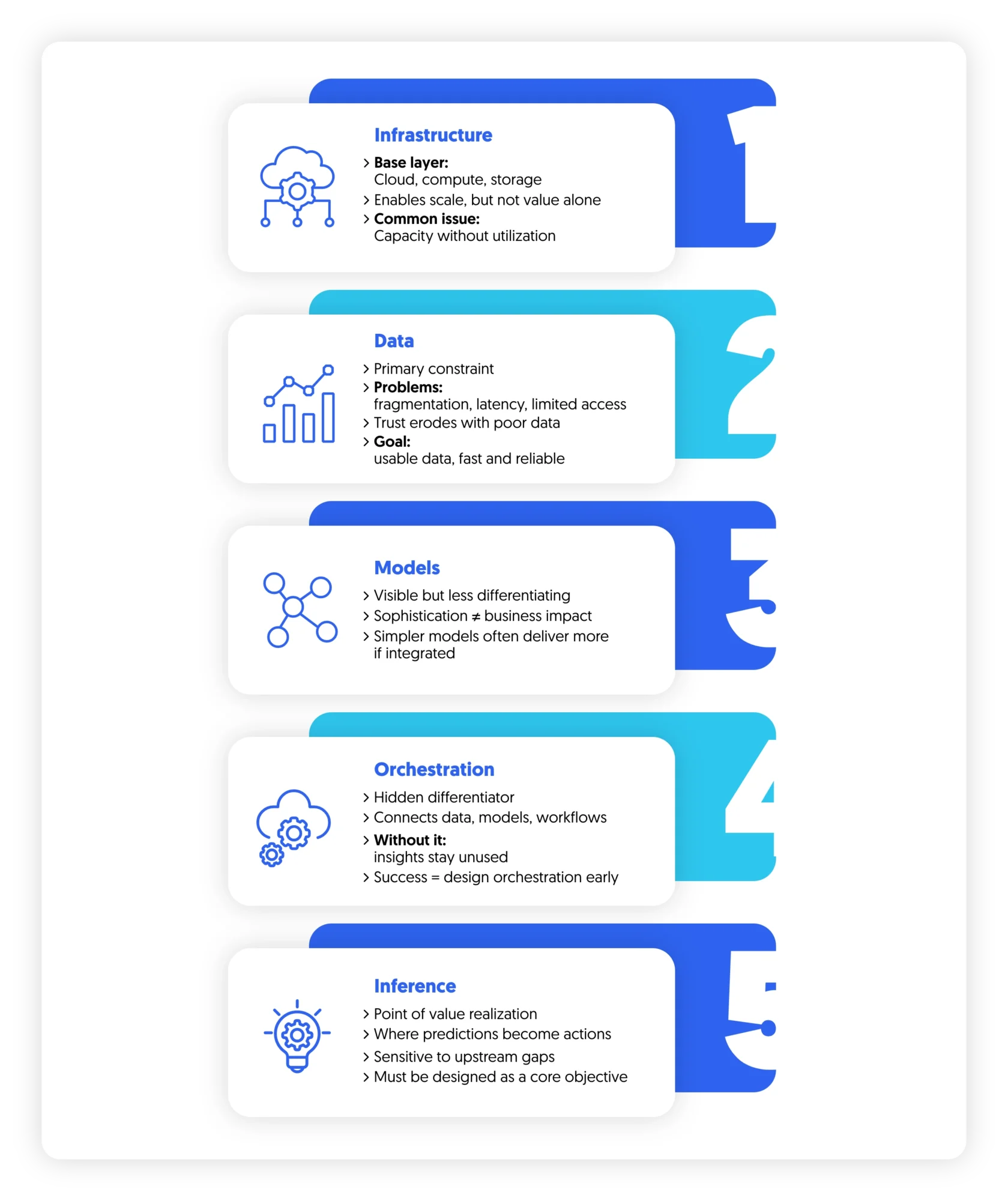
1. Infrastructure: Necessary, Rarely Differentiating
Infrastructure forms the base: cloud environments, compute capacity, storage, and increasingly, access to specialized hardware. Decisions at this layer are often framed as strategic:
- Hyperscaler selection
- Centralized vs federated architectures
- Data residency and sovereignty requirements
These decisions matter, particularly in regulated environments, but they are frequently over-indexed in early-stage AI strategies. The underlying assumption is linear: more compute enables better models, which leads to better outcomes.
In reality, the relationship is conditional. Without aligned data pipelines and clear inference pathways, additional infrastructure does not translate into incremental value. It increases cost, often ahead of proven demand. Many organizations scale infrastructure in anticipation of use cases that are not yet operationally viable.
This creates a recurring inefficiency: capacity without utilization. Infrastructure is an enabler. Its role is to scale what already works not to compensate for what does not.
2. Data: The Primary Constraint
If infrastructure is overestimated, data is consistently underestimated. Data challenges rarely present themselves as outright absence. They appear as friction: inconsistent definitions across systems, fragmentation between business units, latency that prevents real-time use, and limited accessibility outside specialized teams.
These issues are structural, often rooted in how organizations have historically operated. AI systems amplify these weaknesses. A model trained on incomplete or misaligned data does not fail visibly as it produces outputs that appear plausible but lack reliability. This erodes trust over time, reducing adoption even when technical performance appears acceptable.
More critically, data issues compound as organizations attempt to scale: new use cases require additional data integration, each integration introduces new inconsistencies, and governance frameworks slow down access further. Data becomes the rate-limiting factor for AI expansion. Organizations that successfully scale AI tend to treat data as an ongoing capability:
- Continuous structuring and cleaning
- Clear ownership of data domains
- Prioritization of accessibility over theoretical completeness
3. Models: High Visibility, Diminishing Marginal Returns
Models remain the most visible layer and the most misunderstood in terms of impact. Advancements in foundation models have reduced the barrier to entry. Access to high-performing models is increasingly a baseline. Yet, investment patterns have not fully adjusted. Organizations continue to:
- Prioritize model selection early in the process
- Allocate disproportionate resources to fine-tuning
- Use model sophistication as a proxy for progress
This leads to a common misstep: over-engineering before validation.In many use cases, simpler models properly integrated deliver the majority of value. Incremental improvements in model accuracy often produce negligible business impact if:
- Outputs are not embedded into workflows
- Decision-makers do not trust or use the outputs
- Latency prevents timely action
At scale, the constraint shifts from “Can the model predict?” to “Does the organization act on the prediction?”
4. Orchestration: The Hidden Differentiator
Orchestration is where AI transitions from capability to operation. It includes:
- Data pipelines connecting sources to models
- APIs linking models to business systems
- Workflow integration across functions
- Decision logic that determines when and how outputs are used
Despite its importance, orchestration is often underdeveloped. It lacks the visibility of models and the perceived strategic weight of infrastructure. This is where many AI initiatives stall not through failure, but through non-adoption. Typical patterns include: models generating outputs that remain in isolated environments, insights delivered through dashboards instead of embedded actions, manual intervention required to translate outputs into decisions.
In these scenarios, AI creates insight but not impact. Organizations that scale AI successfully invert the typical prioritization: They design orchestration early, sometimes before finalizing the model. This ensures that:
- Outputs have a clear path to execution
- Systems are ready to act as soon as models are viable
- Adoption is built into the design, not addressed post hoc
Orchestration, in effect, determines whether AI becomes part of the operating model or remains adjacent to it.
5. Inference: The Point of Value Realization
Inference is the moment where all upstream layers converge into action. It is where:
- A customer receives a personalized offer
- An employee is guided toward a next-best action
- A process is automated without human intervention
This is the only layer where value is fully realized. However, inference is highly sensitive to upstream misalignment:
- Data latency limits real-time decisioning
- Weak orchestration delays or blocks execution
- Overly complex models increase response times and cost
Organizations often articulate ambitions around real-time, personalized, and autonomous decision-making. Yet their systems are not designed to support these outcomes. The gap between aspiration and reality is most visible at this stage:
- “Real-time” decisions delivered hours later
- “Personalized” interactions based on outdated data
- “Automated” processes requiring manual oversight
Closing this gap requires designing inference as a primary objective, not as a downstream consequence.
Synthesis: Value Emerges from Alignment, Not Optimization
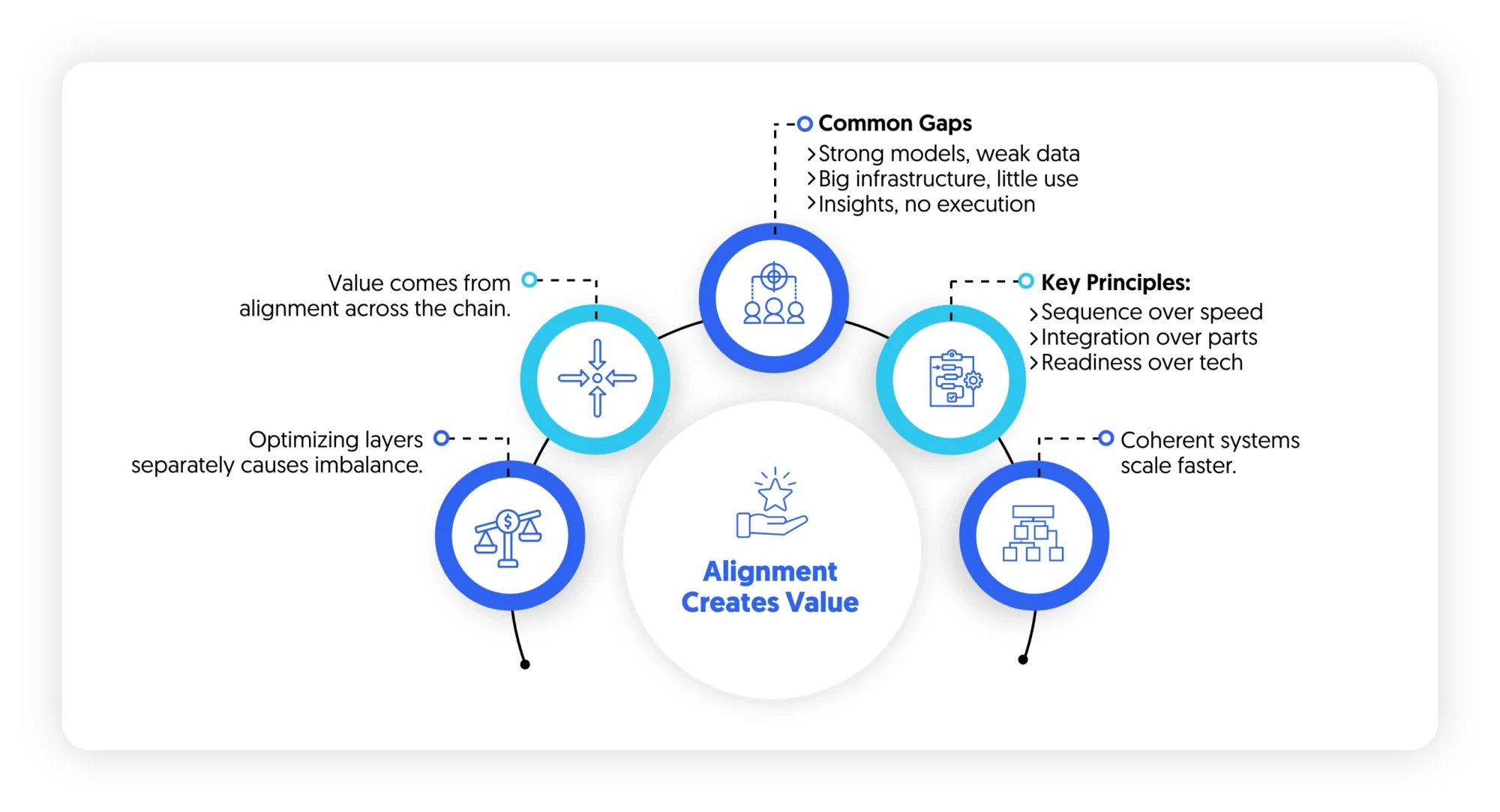
Each layer in the AI value chain can be optimized independently. Many organizations attempt exactly that. Optimizing individual layers does not guarantee system-level performance. In some cases, it creates further imbalance:
- Highly optimized models constrained by weak data
- Scalable infrastructure supporting underutilized use cases
- Advanced insights disconnected from execution
Value in AI comes from alignment across the chain. This has a direct implication for how AI strategies are designed:
- Sequencing matters more than sophistication
- Integration matters more than individual performance
- Operational readiness matters more than technical advancement
Organizations that internalize this shift move faster not because they build more, but because they build coherently.
Where AI Investments Go Wrong
If the AI value chain is well understood conceptually, why do most organizations still struggle to generate returns?
AI funding rarely follows the logic of the value chain. It follows visibility, urgency, and internal narratives about what “progress” looks like. As a result, resources concentrate in areas that signal advancement but do not necessarily unlock value. Over time, this creates a consistent pattern of misallocation.
1. The Visibility Bias: Investing Where Progress Is Seen
Certain layers of the AI value chain are easier to communicate, measure, and showcase:
- Model performance (accuracy, precision, recall)
- Infrastructure scale (compute capacity, cloud migration progress)
These elements translate well into executive updates. They create a sense of momentum. By contrast, the most critical enablers of value are less visible:
- Data standardization across systems
- Workflow integration into frontline operations
- Change management to drive adoption
These do not produce immediate, quantifiable milestones. Progress is slower, more complex, and often cross-functional. The result is a structural bias: Instead of investing where value is created, organizations invest where progress is visible.
2. The Sequencing Problem: Building Before Validating
Many AI programs begin with solution design before validating foundational constraints. Typical sequence:
- Define use cases
- Select or build models
- Attempt to integrate data
- Address workflow implications
This sequence assumes that data and integration challenges are solvable within the delivery phase. In practice, they are often determinative.When data is fragmented or inaccessible, model development slows. When workflows are not clearly defined, outputs lack a path to execution. Teams then compensate:
- Extending timelines
- Expanding scope
- Increasing technical complexity
This leads to a familiar state: pilot environments that never transition to production. A more effective sequence reverses the logic:
- Validate data reality first
- Define where decisions will be executed
- Then design the model to fit those constraints
Without this shift, organizations build capabilities that cannot be operationalized.
3. The Pilot Trap: Local Success, System Failure
Many organizations can point to successful AI pilots:
- A model that predicts churn
- A prototype for automated customer responses
- A dashboard with predictive insights
These pilots often perform well within controlled environments. The challenge emerges when scaling beyond them. Three structural barriers typically appear:
a. Data does not scale
What worked with a curated dataset breaks when exposed to full production complexity.
b. Integration becomes exponential
Each new use case requires additional system connections, increasing technical and organizational friction.
c. Ownership becomes unclear
Pilots are often owned by innovation or analytics teams. Scaling requires transfer to operational teams that were not involved in initial development. The result is fragmentation: multiple successful pilots, no systemic impact.
4. The Over-Engineering Bias: Solving for Complexity Too Early
In the absence of clear constraints, teams tend to design for maximum flexibility and performance. This manifests as:
- Selection of complex model architectures
- Extensive feature engineering
- Broad, multi-use-case platforms
While technically robust, these approaches introduce:
- Longer development cycles
- Higher maintenance requirements
- Increased dependency on specialized talent
More importantly, they delay time to value. In many cases, simpler solutions would deliver 70–80% of the value in a fraction of the time while enabling faster iteration based on real usage.
5. The Adoption Gap: Insight Without Action
Even when AI systems are technically sound, value depends on whether outputs influence decisions.This is where many initiatives underperform. Common patterns include:
- Insights delivered through dashboards that require manual interpretation
- Recommendations that are not trusted by frontline teams
- Processes that remain unchanged despite new capabilities
The gap is operational. AI outputs must compete with:
- Established ways of working
- Incentive structures
- Time constraints of frontline roles
If acting on AI requires additional effort, it will not scale regardless of model quality. Organizations that close this gap design for embedded decision-making:
- Outputs integrated directly into workflows
- Clear ownership of actions
- Feedback loops to refine performance
Without this, AI remains advisory rather than transformative.
6. The Missing Operating Model
Underlying all these issues is a broader structural gap: AI is introduced without redefining how the organization operates.
Key questions often remain unresolved:
- Who owns AI-driven decisions?
- How are models monitored and updated?
- How are trade-offs managed between automation and control?
- How are incentives aligned with AI adoption?
In the absence of clear answers, organizations default to existing structures, which were not designed for AI-enabled operations. This creates friction at every layer:
- Data access slowed by governance designed for reporting, not real-time use
- Models disconnected from business ownership
- Orchestration limited by fragmented system accountability
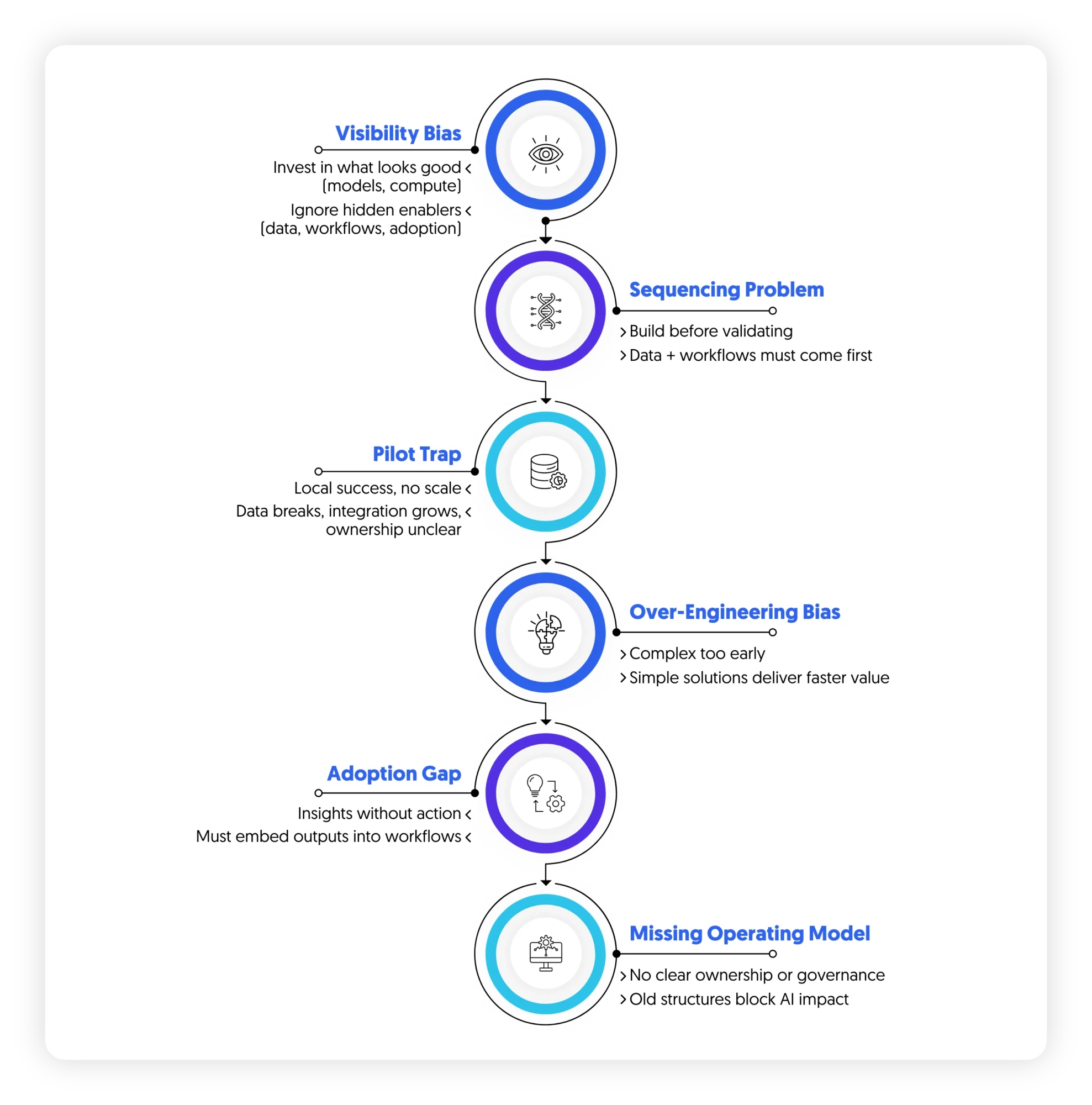
Synthesis: Misalignment Is Systemic
These patterns are not independent. They reinforce each other:
- Visibility bias drives overinvestment in models and infrastructure
- Poor sequencing exposes data and integration constraints late
- Pilot success masks scaling challenges
- Over-engineering delays value realization
- Lack of operating model prevents adoption
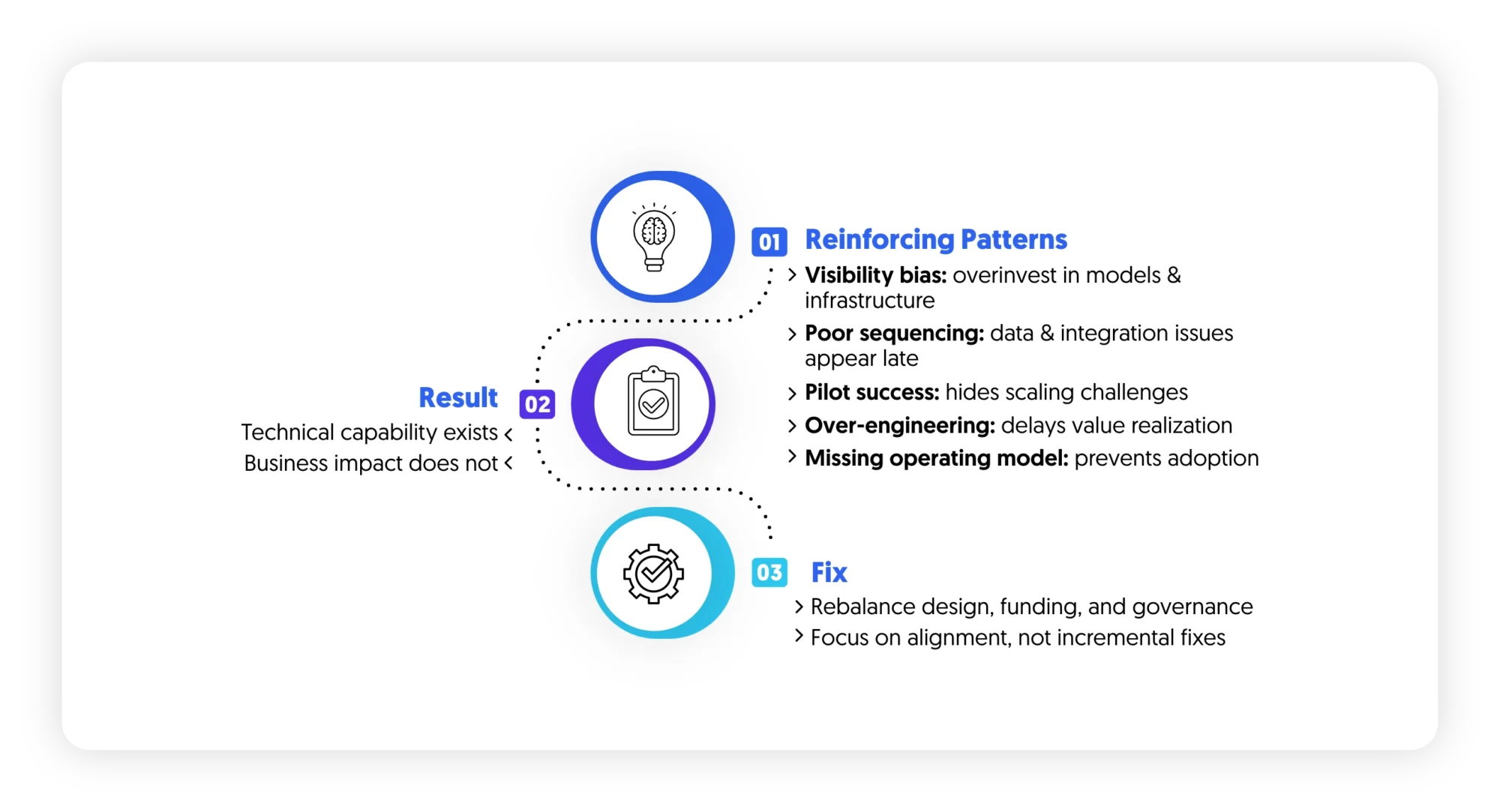
Together, they create a system where:
- Technical capability exists
- Business impact does not
Correcting this requires rebalancing how AI programs are designed, funded, and governed rather than incremental fixes.
What a Balanced AI Stack Looks Like
Most AI strategies describe ambition: “become data-driven,” “scale AI across the enterprise,” or “embed intelligence into decision-making.” Few describe the operational reality required to make that happen.
A balanced AI stack is defined by alignment across layers so that value can flow from data to decision without friction.In organizations that successfully scale AI, the stack behaves less like a set of technologies and more like a production system for decisions.
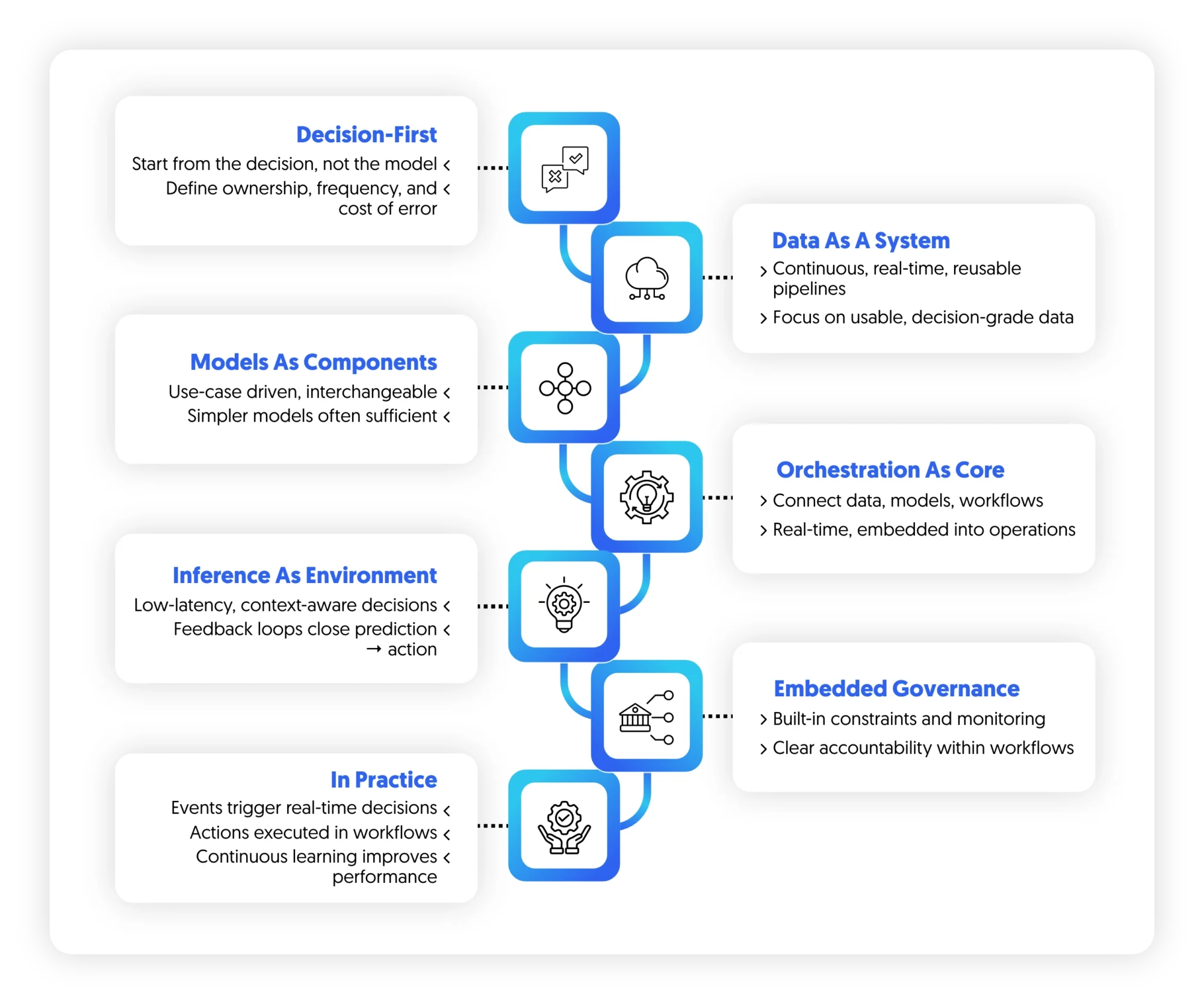
1. Principle One: Design Starts from the Decision, Not the Model
In most AI programs, model selection is the starting point. In scaled environments, it is the endpoint. The starting point is always the decision:
- What decision is being influenced or automated?
- Who owns it today?
- At what frequency is it made?
- What is the cost of error or delay?
This immediately constrains everything downstream:
- Data requirements become clearer
- Model complexity becomes bounded
- Integration needs become explicit
Without this anchoring point, AI systems tend to optimize for technical performance rather than operational relevance. A balanced stack is therefore decision-first, not model-first.
2. Principle Two: Data Is Treated as a Continuous System, Not a Project
In immature stacks, data is treated as a preparatory phase: “Fix data first, then build AI.” In balanced systems, this assumption is removed. Data is treated as a continuous operational layer, not a one-time cleanup exercise. This shift changes how organizations behave:
- Data quality is monitored in real time, not periodically audited
- Ownership is distributed across domains, not centralized in a single team
- Data pipelines are designed for reuse across multiple decision flows
Most importantly, data is optimized for speed of access and usability, not theoretical completeness. In this way, perfect data is not what is required but reliable, decision-grade data.
3. Principle Three: Models Are Commoditized, Not Centralized
In mature AI stacks, models are interchangeable components within a broader system. This leads to three important shifts:
- Model selection becomes use-case driven, not platform driven
- Multiple models may coexist for different decision types
- Simpler models are preferred when they meet performance thresholds
The key constraint is no longer “Can we build a better model?”It becomes “Does this model improve the decision in production conditions?”
This reduces over-engineering and accelerates deployment cycles. Model strategy shifts from optimization to sufficiency.
4. Principle Four: Orchestration Becomes the Core Layer
If there is a single structural difference between experimental and scaled AI systems, it is orchestration. Orchestration determines whether intelligence remains isolated or becomes operational. A balanced orchestration layer includes:
- Real-time data pipelines
- API-driven connectivity between systems
- Workflow integration into core business processes
- Event-driven triggers that activate decisions automatically
This layer is where AI either disappears into operations or remains visible as a separate tool. In mature systems, users do not “use AI.” They experience outcomes shaped by AI within their normal workflows. That distinction is critical.
5. Principle Five: Inference Is Designed as an Operating Environment
In many organizations, inference is treated as a technical endpoint.In balanced systems, it is treated as an operating environment where decisions are continuously produced and executed.
This requires:
- Low-latency decisioning for time-sensitive use cases
- Context-aware outputs based on real-time signals
- Embedded feedback loops to refine performance
- Clear escalation paths when automation thresholds are exceeded
Inference is about closing the loop between prediction and action. Without this design, even highly accurate models fail to create measurable impact.
6. Principle Six: Governance Is Embedded, Not Layered On Top
Traditional governance models are often applied after system design:
- Review boards
- Approval workflows
- Post-hoc audits
In a balanced AI stack, governance is embedded into the system itself.
This includes:
- Built-in constraints within workflows (what the system can and cannot do)
- Real-time monitoring of model behavior and drift
- Audit trails integrated into orchestration layers
- Clear accountability mapped to business owners, not just technical teams
Governance shifts from being a control function to an architectural property of the system. This is particularly critical in agentic and automated environments, where decisions are executed without human intervention.
7. What This Looks Like in Practice
When these principles are combined, the AI stack behaves differently: Instead of:
- Models generating insights
- Dashboards visualizing outputs
- Teams manually acting on recommendations
The system becomes:
- Events triggering decisions in real time
- Actions executed within operational workflows
- Continuous learning loops improving performance
The key shift is structural: AI moves from being a layer of analysis to a layer of execution.
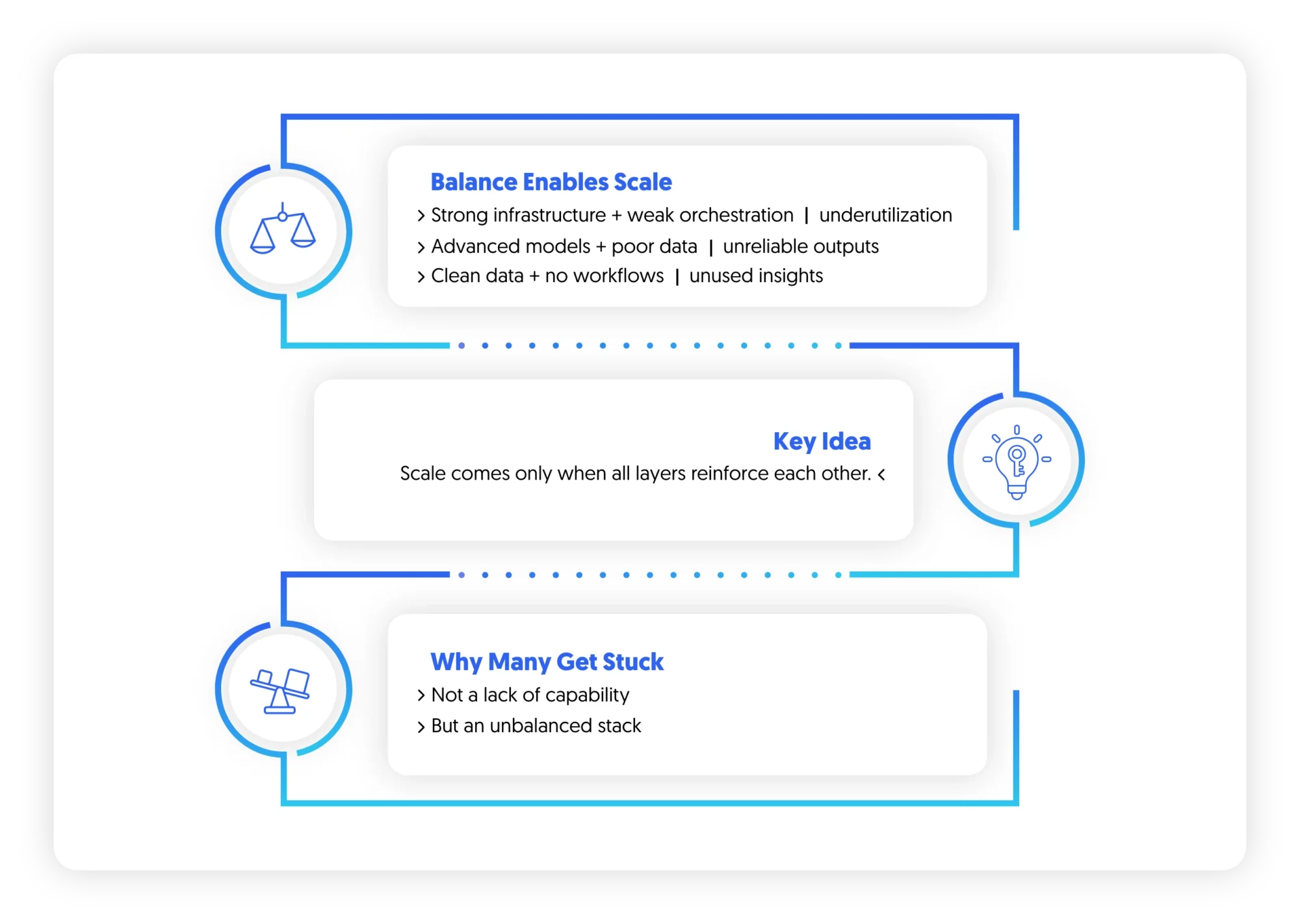
Synthesis: Balance Is What Enables Scale
A balanced AI stack ensures that no layer becomes a bottleneck.
- Strong infrastructure without orchestration leads to underutilization
- Advanced models without data alignment lead to unreliable outputs
- Clean data without embedded workflows leads to unused insights
Scale emerges only when all layers are designed to reinforce each other. This is why many organizations remain stuck in pilot mode: Not because they lack capability, but because their stack is asymmetrically developed.
Implications for CX, EX, and Enterprise Transformation
AI stops being a technology discussion the moment it is deployed inside real operational environments. At that point, it becomes a question of how organizations make decisions, how they serve customers, and how employees execute work. This is where most AI strategies lose coherence. They remain structured around tools and capabilities, while the enterprise operates around journeys, processes, and decisions.
The gap between the two is where value is either created or lost.
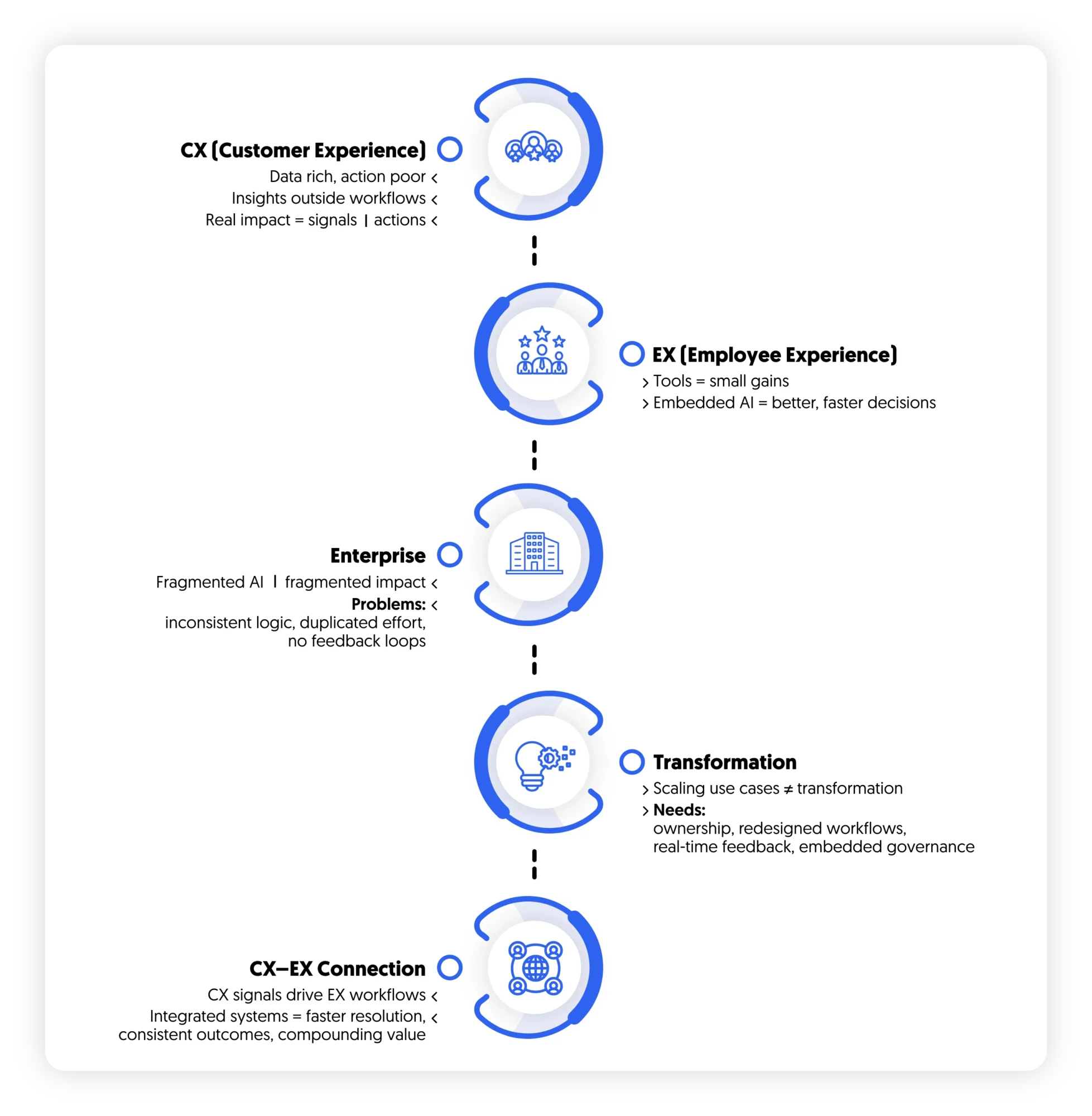
1. AI in CX: The Breakdown Between Insight and Action
Customer experience environments are already rich in data:
- Behavioral signals across digital channels
- Transactional history
- Voice of customer feedback
- Operational service data
Most organizations have the insight , but lack activation mechanisms. The typical CX AI stack produces:
- Predictive dashboards
- Segmentation models
- Sentiment analysis reports
But the operating reality remains unchanged:
- Agents still act on static scripts
- Marketing still runs predefined journeys
- Service teams still respond reactively
The disconnect is structural. Insights are generated outside the workflow where decisions are made. In a functioning AI-enabled CX system:
- Customer signals trigger real-time actions
- Next-best actions are embedded directly into agent interfaces
- Journey adjustments happen dynamically, not periodically
The shift is not from insight generation to better insight generation.It is from analysis to execution within the flow of customer interaction.Without this shift, CX AI remains observational rather than transformative.
2. AI in EX: From Productivity Tools to Decision Systems
In employee experience, AI is often positioned as a productivity enhancer:
- Summarizing information
- Automating administrative tasks
- Supporting knowledge retrieval
While valuable, this framing is limited. It treats AI as a set of tools that assist work, rather than systems that shape how work is done. The deeper opportunity lies in decision augmentation:
- Prioritizing tasks based on operational impact
- Guiding employees toward next-best actions
- Automating low-value decisions entirely
In practice, EX transformation depends on whether AI is embedded into core workflows or layered on top of them.
When AI is embedded:
- Employees spend less time searching and more time acting
- Decision quality becomes more consistent across teams
- Operational variability decreases
When AI is additive:
- Employees toggle between systems
- Insights are manually interpreted
- Productivity gains remain marginal
3. The Enterprise Problem: Fragmented AI Equals Fragmented Impact
Most enterprises have a fragmentation problem masked as a capability problem. AI initiatives are typically distributed across:
- Business units
- Functional teams
- Innovation hubs
- Vendor-led programs
Each initiative may be successful in isolation. But they are rarely connected through a unified value chain.This leads to three systemic issues:
a. Inconsistent Decision Logic
Different teams use different models, thresholds, and definitions of success, leading to variability in outcomes.
b. Duplicated Capability Building
Multiple teams solve similar problems independently, increasing cost and reducing scalability.
c. Lack of Feedback Loops
Insights generated in one part of the organization rarely improve systems elsewhere.The result is an enterprise where AI exists, but does not compound.
4. Transformation Requirement: From Use Cases to Operating Model
The core misconception in many AI strategies is that transformation is achieved through scaling use cases.
In reality, scaling use cases without changing the operating model leads to complexity, not transformation.
What changes instead is structural:
Decision Ownership
Clear accountability for AI-driven decisions embedded within business functions, not isolated in analytics teams.
Workflow Redesign
Processes re-engineered so that AI outputs are not external inputs but embedded triggers.
Real-Time Feedback Loops
Systems continuously learning from outcomes, not periodically retrained in isolation.
Governance as Design
Control mechanisms embedded into system architecture rather than imposed externally.
This is what separates AI adoption from AI transformation.
5. The CX–EX Connection: Where Value Ultimately Compounds
The most advanced organizations are beginning to converge CX and EX through AI-driven systems.This is operational:
- CX signals trigger internal workflows
- EX systems determine how employees respond
- Feedback loops connect customer outcomes to employee actions
When these systems are integrated:
- Customer issues are resolved faster
- Employee decisions become more consistent
- Organizational learning accelerates
This is where AI shifts from efficiency to compounding advantage.
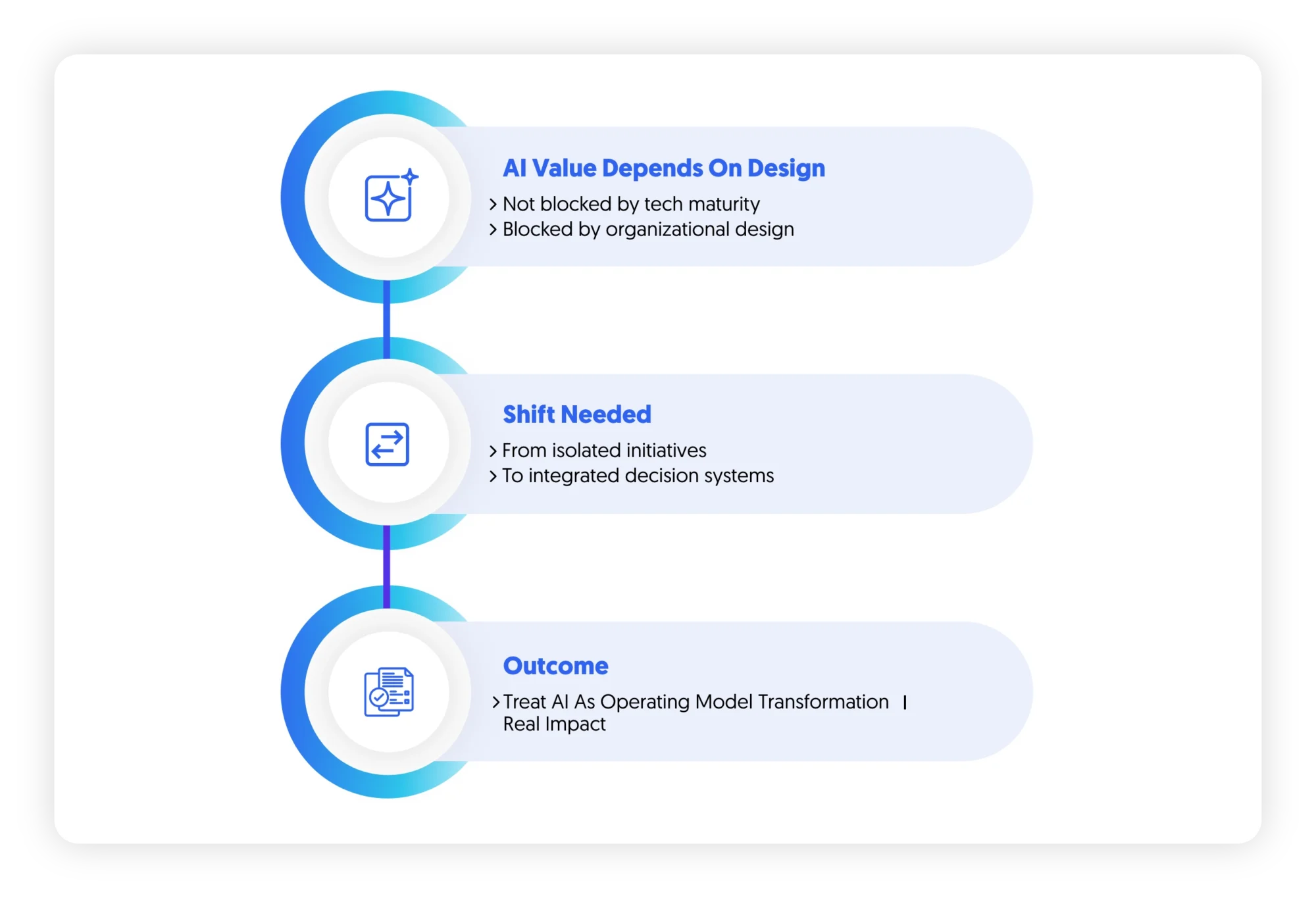
Final Synthesis: AI as an Operating Model Shift
Across CX, EX, and enterprise systems, a consistent pattern emerges: AI value is constrained by organizational design. The real shift is the transition from: Isolated AI initiatives to Integrated decision systems embedded in how the enterprise operates
Organizations that treat AI as a transformation of the operating model—not a collection of use cases—will move beyond experimentation. Those that do not will continue to see AI as a set of promising but disconnected capabilities.